人脸识别算法
两大开源人脸识别算法:insightface和facenet,包括算法效果与性能,facenet使用的是较早的softmax,Python3环境,基于tensorflow实现;insightface使用的是18年出的arcface,Python2环境,基于mxnet实现。关于不同loss函数的区别,可以参看人脸识别损失函数综述。
参考:https://zhuanlan.zhihu.com/p/52560499
人脸检测算法
人脸检测算法综述
参考:https://blog.csdn.net/wfei101/article/details/80542903
人脸检测的目标是找出图像中所有的人脸对应的位置,算法的输出是人脸外接矩形在图像中的坐标,可能还包括姿态如倾斜角度等信息。下面是一张图像的人脸检测结果:

虽然人脸的结构是确定的,由眉毛、眼睛、鼻子和嘴等部位组成,近似是一个刚体,但由于姿态和表情的变化,不同人的外观差异,光照,遮挡的影响,准确的检测处于各种条件下的人脸是一件相对困难的事情。
人脸检测算法要解决以下几个核心问题:
- 1、人脸可能出现在图像中的任何一个位置
- 2、人脸可能有不同的大小
- 3、人脸在图像中可能有不同的视角和姿态
- 4、人脸可能部分被遮挡
经典的人脸检测算法流程是这样的:用大量的人脸和非人脸样本图像进行训练,得到一个解决2类分类问题的分类器,也称为人脸检测模板。这个分类器接受固定大小的输入图片,判断这个输入图片是否为人脸,即解决是和否的问题。人脸二分类器的原理如下图所示:
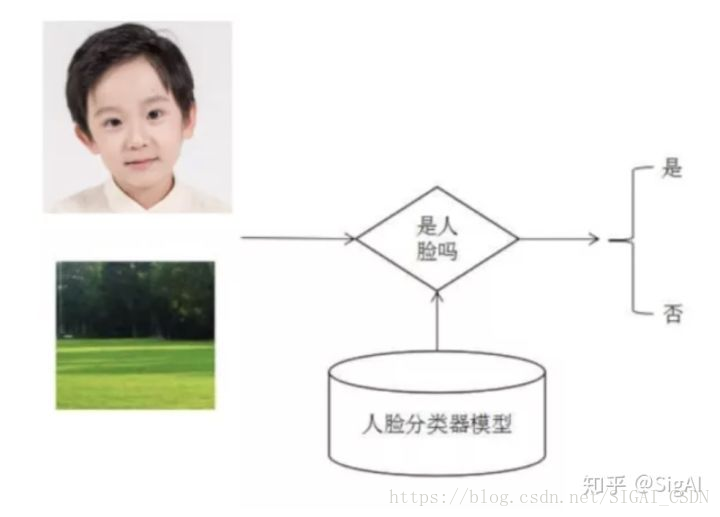
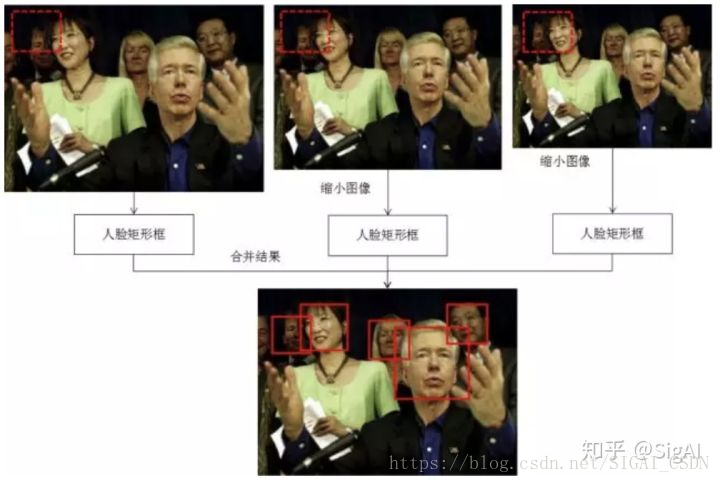
由于人脸可能出现在图像的任何位置,在检测时用固定大小的窗口对图像从上到下、从左到右扫描,判断窗口里的子图像是否为人脸,这称为滑动窗口技术(sliding window)。为了检测不同大小的人脸,还需要对图像进行放大或者缩小构造图像金字塔,对每张缩放后的图像都用上面的方法进行扫描。由于采用了滑动窗口扫描技术,并且要对图像进行反复缩放然后扫描,因此整个检测过程会非常耗时。
由于一个人脸附件可能会检测出多个候选位置框,还需要将检测结果进行合并去重,这称为非极大值抑制(NMS)。多尺度滑动窗口技术的原理如下图所示:

我们将整个人脸检测算法分为3个阶段,分别是早期算法,AdaBoost框架,以及深度学习时代,在接下来将分这几部分进行介绍。
早期算法
早期的人脸检测算法使用了模板匹配技术,即用一个人脸模板图像与被检测图像中的各个位置进行匹配,确定这个位置处是否有人脸;此后机器学习算法被用于该问题,包括神经网络,支持向量机等。以上都是针对图像中某个区域进行人脸-非人脸二分类的判别。
早期有代表性的成果是Rowley等人提出的方法[1][2]。他们用神经网络进行人脸检测,用20x20的人脸和非人脸图像训练了一个多层感知器模型。文献[1]的方法用于解决近似正面的人脸检测问题,原理如下图所示: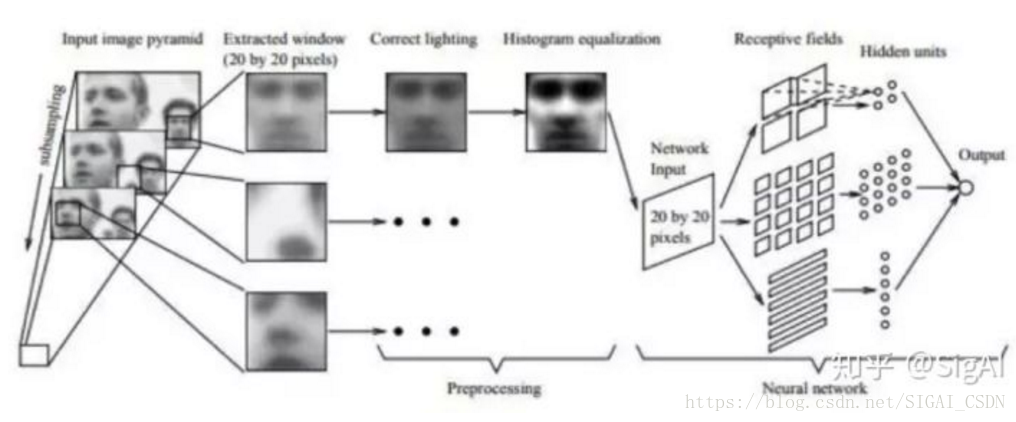
文献[2]的方法解决多角度人脸检测问题,整个系统由两个神经网络构成,第一个网络用于估计人脸的角度,第二个用于判断是否为人脸。角度估计器输出一个旋转角度,然后用整个角度对检测窗进行旋转,然后用第二个网络对旋转后的图像进行判断,确定是否为人脸。系统结构如下图所示: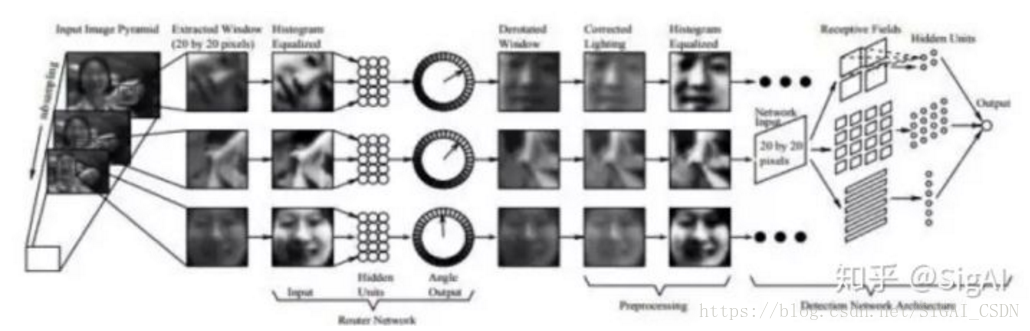
Rowley的方法有不错的精度,由于分类器的设计相对复杂而且采用的是密集滑动窗口进行采样分类导致其速度太慢。
AdaBoost框架
接下来介绍AdaBoost框架之后的方法,boost算法是基于PAC学习理论(probably approximately correct)而建立的一套集成学习算法(ensemble learning)。其根本思想在于通过多个简单的弱分类器,构建出准确率很高的强分类器,PAC学习理论证实了这一方法的可行性,感谢大神Leslie-Valiant!!我们首先来看FDDB上各种检测算法的ROC曲线,接下来的介绍将按照这些ROC曲线上的算法进行展开。
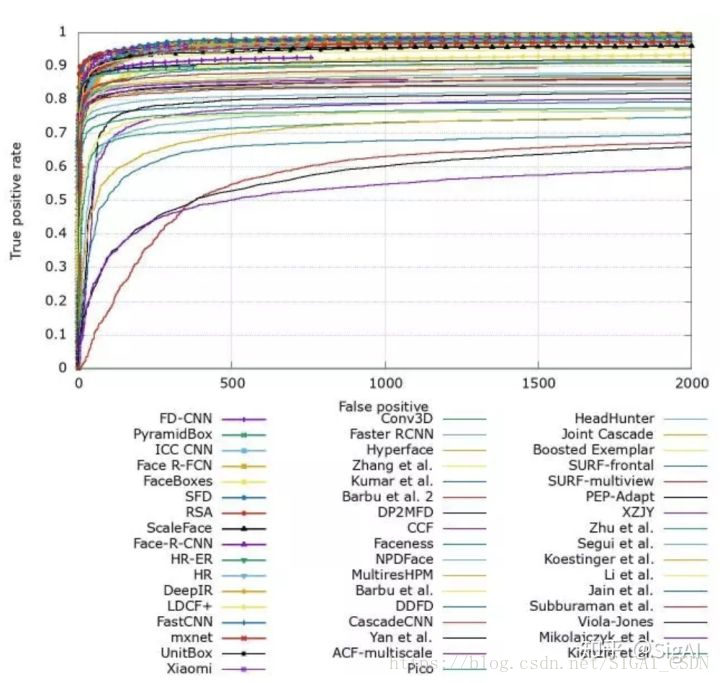
在2001年Viola和Jones设计了一种人脸检测算法[10]。它使用简单的Haar-like特征和级联的AdaBoost分类器构造检测器,检测速度较之前的方法有2个数量级的提高,并且保持了很好的精度,我们称这种方法为VJ框架。VJ框架是人脸检测历史上第一个最具有里程碑意义的一个成果,奠定了基于AdaBoost目标检测框架的基础,所以作为重点和大家唠唠。
用级联AdaBoost分类器进行目标检测的思想是:用多个AdaBoost分类器合作完成对候选框的分类,这些分类器组成一个流水线,对滑动窗口中的候选框图像进行判定,确定它是人脸还是非人脸。
在这一系列AdaBoost分类器中,前面的强分类器设计很简单,包含的弱分类器很少,可以快速排除掉大量的不是人脸的窗口,但也可能会把一些不是人脸的图像判定为人脸。如果一个候选框通过了第一级分类器的筛选即被判定为人脸,则送入下一级分类器中进行判定,以此类推。如果一个待检测窗口通过了所有的强分类器,则认为是人脸,否则是非人脸。下图是分类器级联进行判断的示意图:
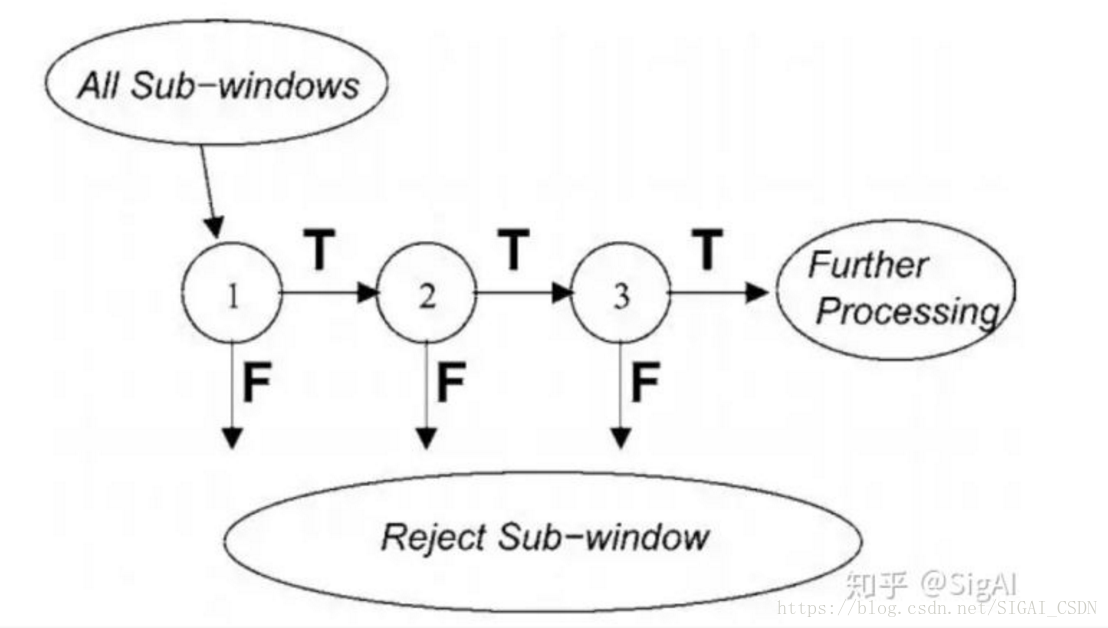
这种思想的精髓在于用简单的强分类器在初期快速排除掉大量的非人脸窗口,同时保证高的召回率,使得最终能通过所有级强分类器的样本数很少。这样做的依据是在待检测图像中,绝大部分都不是人脸而是背景,即人脸是一个稀疏事件,如果能快速的把非人脸样本排除掉,则能大大提高目标检测的效率。
出于性能考虑,弱分类器使用了简单的Haar-like特征,这种特征源自于小波分析中的Haar小波变换,Haar小波是最简单的小波函数,用于对信号进行均值、细节分解。这里的Haar-like特征定义为图像中相邻矩形区域像素之和的差值。下图是基本Haar-like特征的示意图: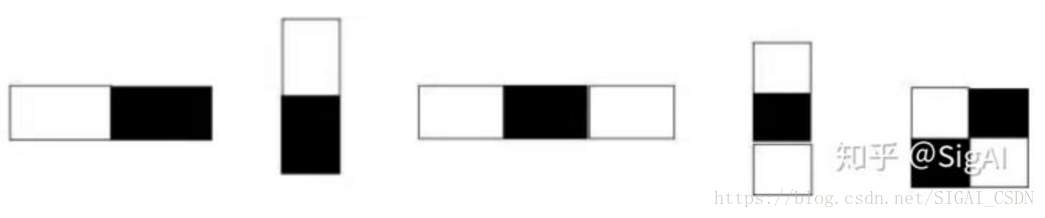
Haar-like特征是白色矩形框内的像素值之和,减去黑色区域内的像素值之和。以图像中第一个特征为例,它的计算方法如下:首先计算左边白色矩形区域里所有像素值的和,接下来计算右边黑色矩形区域内所有像素的和,最后得到的Haar-like特征值为左边的和减右边的和。
这种特征捕捉图像的边缘、变化等信息,各种特征描述在各个方向上的图像变化信息。人脸的五官有各自的亮度信息,很符合Haar-like特征的特点。
在深度学习出现以前工业界的方案都是基于VJ算法。但VJ算法仍存在一些问题:
- (1)Haar-like特征是一种相对简单的特征,其稳定性较低;
- (2)弱分类器采用简单的决策树,容易过拟合。因此,该算法对于解决正面的 人脸效果好,对于人脸的遮挡,姿态,表情等特殊且复杂的情况,处理效果不理想(虽然有了一些改进方案,但还是不够彻底!!)。
- (3)基于VJ-cascade的分类器设计,进入下一个stage后,之前的信息都丢弃了,分类器评价一个样本不会基于它在之前stage的表现——这样的分类器鲁棒性差。
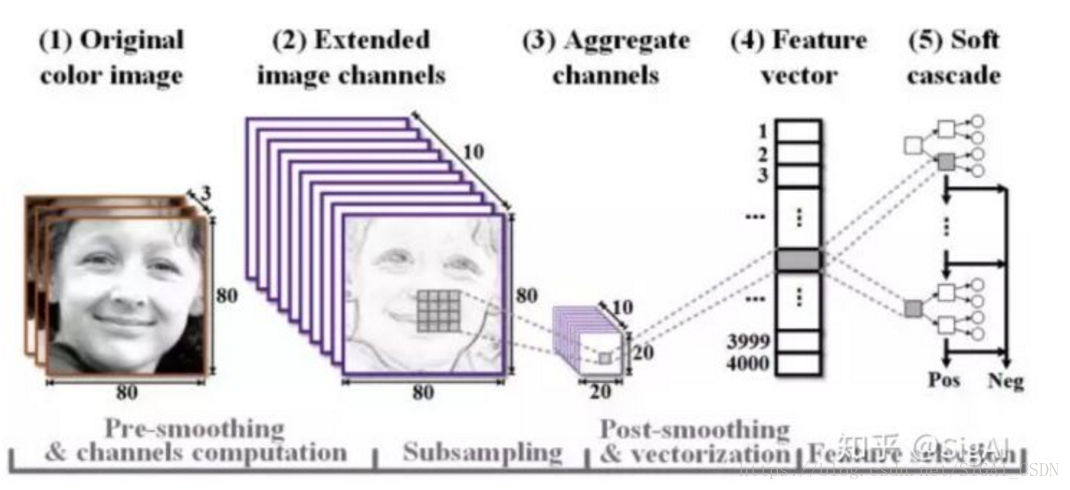
ACF[15](Aggregate ChannelFeatures for Multi-view Face Detection)是一种为分类提供足够多的特征选择的方法。在对原图进行处理后,得到多通道的图像,这些通道可以是RGB的通道,可以是平滑滤波得到的,可以是x方向y方向的梯度图等等。将这些通道合起来,在此基础上提取特征向量后续采用Soft-Cascade分类器进行分类。
相较于VJ-cascade的设计,Soft-Cascade采用几个改进的方案:
(1)每个stage的决策函数不是二值而是标量值(scalar-valued) ,且与该样本有多"容易"通过这个stage以及在这个stage的相对重要性成比例。(2)生成的决策函数是需要通过之前每个阶段的值而不单单是本阶段来判定。(3)文中把检测器的运行时间-准确率权衡通过一个叫ROC surface的3维曲面清楚的展示出来,方便调节参数,可以明确的知道动了哪个参数会对这个检测器的性能会有些什么影响。
DMP模型
DPM(Deformable Part Model),正如其名称所述,可变形的组件模型,是一种基于组件的检测算法,其所见即其意。该模型由Felzenszwalb在2008年提出,并发表了一系列的CVPR,NIPS会议。并且还拿下了2010年,PASCAL VOC的“终身成就奖”。
由于DPM算法[16]本身是一种基于组件的检测算法,所以对扭曲,性别,多姿态,多角度等的人脸都具有非常好的检测效果(人脸通常不会有大的形变,可以近似为刚体,基于DMP的方法可以很好地处理人脸检测问题)。

DPM的方法采用的是FHOG进行特征的提取,作者对HOG进行了很大的改动,没有直接采用49=36维向量,而是对每个8x8的cell提取18+9+4=31维特征向量。作者还讨论了依据PCA(Principle Component Analysis)可视化的结果选9+4维特征,能达到HOG 49维特征的效果。基于DPM的方法在户外人脸集上都取得了比Viola-Jones更好的效果,但是由于该模型过于复杂,判断时计算复杂,很难满足实时性的要求。后续有了一些列改进的流程,比如加入级联分类器,针对特征计算采用了积分图的方法等,但都还没有达到VJ方法的效率。
DPM模型一个大的问题是速度太慢,因此在工程中很少使用,一般采用的是AdaBoost框架的算法。
基于经典的人工设计特征本身稳定性并不稳定,容易受外界环境的影响(光照、角度、遮挡等),所以在复杂场景下的人脸检测性能很难的到保证,只能应用到受限的场景中。深度学习出现以后,DCNN(深度卷积神经网络)能很好的学习到图像中目标物各个层级的特征,对外界的抗干扰能力更强,后序的人脸检测方法基本都基于DCNN的特征来优化了。
深度学习框架
卷积神经网络在图像分类问题上取得成功之后很快被用于人脸检测问题,在精度上大幅度超越之前的AdaBoost框架,当前已经有一些高精度、高效的算法。直接用滑动窗口加卷积网络对窗口图像进行分类的方案计算量太大很难达到实时,使用卷积网络进行人脸检测的方法采用各种手段解决或者避免这个问题。
Cascade CNN
Cascade CNN[17]可以认为是传统技术和深度网络相结合的一个代表,和VJ人脸检测器一样,其包含了多个分类器,这些分类器采用级联结构进行组织,然而不同的地方在于,Cascade CNN采用卷积网络作为每一级的分类器。
构建多尺度的人脸图像金字塔,12-net将密集的扫描这整幅图像(不同的尺寸),快速的剔除掉超过90%的检测窗口,剩下来的检测窗口送入12-calibration-net调整它的尺寸和位置,让它更接近潜在的人脸图像的附近。

采用非极大值抑制(NMS)合并高度重叠的检测窗口,保留下来的候选检测窗口将会被归一化到24x24作为24-net的输入,这将进一步剔除掉剩下来的将近90%的检测窗口。和之前的过程一样,通过24-calibration-net矫正检测窗口,并应用NMS进一步合并减少检测窗口的数量。
将通过之前所有层级的检测窗口对应的图像区域归一化到48x48送入48-net进行分类得到进一步过滤的人脸候选窗口。然后利用NMS进行窗口合并,送入48-calibration-net矫正检测窗口作为最后的输出。

Cascade CNN一定程度上解决了传统方法在开放场景中对光照、角度等敏感的问题,但是该框架的第一级还是基于密集滑动窗口的方式进行窗口过滤,在高分辨率存在大量小人脸(tiny face)的图片上限制了算法的性能上限。
RetinaFace
参考:https://blog.csdn.net/u011622208/article/details/90266711
名为RetinaFace是nsight Face在2019年提出的最新人脸检测模型(单阶段人脸检测器),它利用联合监督和自我监督的多任务学习,在各种人脸尺度上执行像素方面的人脸定位。
深度学习框架
InsightFace
准备
1、下载insightface仓库:
git clone https://gitee.com/yxkhuijie/insightface.git
2、准备数据
下载WIDERFACE数据集:
官方下载地址:http://shuoyang1213.me/WIDERFACE/WiderFace_Results.html
阿里云盘地址:
